Zacznijmy od tego, czym jest LLM (Large Language Model)?
Są to algorytmy sztucznej inteligencji wyszkolone na olbrzymich ilościach danych, co pozwala im na analizę i generowanie języka naturalnego. Poprzez takie szkolenie umieją wyłapywać wzorce i zależności między słowami. Co za tym idzie jeśli dany model uczony był na starszych materiałach, może nie być w stanie zrozumieć niektórych sformułowań.
LLM, czyli Large Language Model, to zaawansowany algorytm sztucznej inteligencji wyszkolony na ogromnych zbiorach danych tekstowych. To właśnie dlatego potrafi analizować i generować tekst w języku naturalnym, rozpoznając wzorce i zależności pomiędzy słowami. Jednak warto mieć na uwadze, że jeśli model był uczony na starszych materiałach, może mieć trudności z rozumieniem nowszych sformułowań czy slangowych wyrażeń.
Jak są zbudowane LLMy?
Duże modele językowe (LLMy) opierają się na architekturze sieci neuronowych. Sieci te składają się z trzech głównych elementów: warstwy wejściowej, warstw ukrytych oraz warstwy wyjściowej. To właśnie ta struktura sprawia, że modele są niedeterministyczne – mogą generować różne odpowiedzi na to samo pytanie, nawet jeśli warunki początkowe są identyczne.
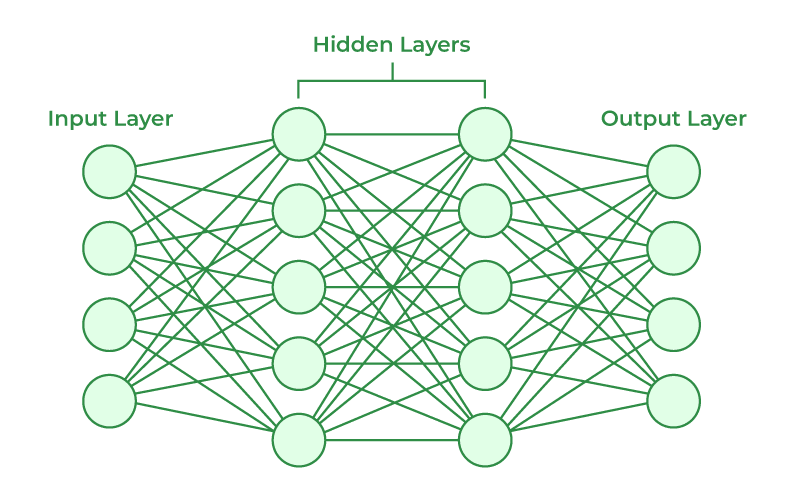
źródło: GeeksForGeeks
W praktyce wygląda to następująco: warstwa wejściowa przyjmuje dane wejściowe, takie jak tekst czy obrazy. Kolejne, tak zwane warstwy ukryte, zawierają neurony odpowiedzialne za przetwarzanie tych danych. Im więcej warstw (i neuronów), tym bardziej złożone zależności sieć neuronowa może rozpoznawać. Ostatecznie warstwa wyjściowa generuje odpowiedź na podstawie przetworzonych informacji.
Przyjrzyjmy się prostemu przykładowi, żeby zobrazować działanie sieci neuronowych. Załóżmy, że mamy model LLM zaprojektowany do rozpoznawania zdjęć przedstawiających śpiące pieski. Niech poniższy obraz posłuży nam jako przykład danych wejściowych:

W procesie analizy sieć neuronowa przetwarza obraz w kilku etapach. Warstwy ukryte analizują różne cechy obrazu, takie jak kształty, tekstury czy wzorce, aby określić, czy dany obraz przedstawia psa. Każdy neuron w tych warstwach „uczy się” wyłapywać specyficzne cechy, które są istotne dla klasyfikacji.
Na końcu, w warstwie wyjściowej, model zwraca rezultat – określenie, czy obraz przedstawia śpiącego pieska. Ważne jest jednak, że odpowiedź nie jest jednoznaczna, lecz podawana z pewnym prawdopodobieństwem. Im bardziej zaawansowane i odpowiednio wytrenowane są warstwy ukryte, tym większa precyzja wyników. Jednak mimo wszystko mówimy o prawdopodobieństwie poprawnego poprawnej odpowiedzi, dlatego model pozostaje niedeterministyczny.
Czym są tokeny?
W kontekście modeli LLM często pojawia się termin token, ale co to dokładnie oznacza? Mówiąc najprościej, token to fragment tekstu, który model przetwarza w trakcie generowania odpowiedzi. Może to być całe słowo, pojedyncza litera, znak interpunkcyjny lub nawet część wyrazu – wszystko zależy od sposobu, w jaki model został skonfigurowany.
Aby zobaczyć, jak to działa w praktyce, można skorzystać z narzędzi takich jak Tiktokenizer, który wizualizuje podział tekstu na tokeny:
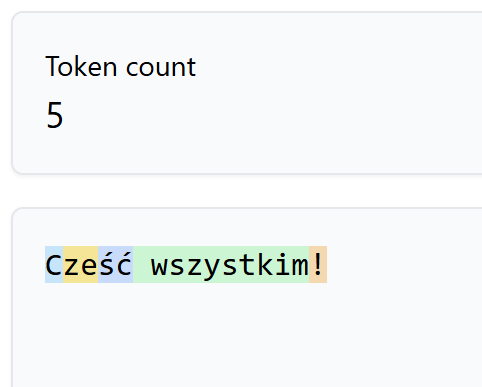
Na powyższym przykładzie widać, jak tekst został podzielony na tokeny. Warto zauważyć, że sposób podziału zależy od konkretnego modelu – w tym przypadku użyłem modelu GPT-4o. Każdy token jest reprezentowany przez unikalny identyfikator numeryczny, który umożliwia modelowi analizę tekstu i generowanie odpowiednich odpowiedzi.

Tokeny mają kluczowe znaczenie dla wydajności i kosztów użycia modelu. Większe fragmenty tekstu wymagają więcej zasobów obliczeniowych do przetworzenia. Niekiedy nawet możemy przekroczyć ilość tokenów wejściowych, które jest w stanie przetworzyć dany model. Dlatego optymalizacja liczby tokenów jest istotna przy pracy z dużymi modelami językowymi.
Jak LLM generuje odpowiedź?
Już wiemy, że do wygenerowana odpowiedź składa się z tokenów, ale jak to się dzieje? Podczas udzielania odpowiedzi model jest w stanie wygenerować jeden token na raz. Co za tym idzie proces generowania odpowiedzi musi być powtórzony wielokrotnie, co jesteśmy w stanie zauważyć podczas generowania odpowiedzi na przykład przez ChatGPT czy Gemini.
Dodatkowo model bazuje na dotychczasowej konwersacji. Generując odpowiedź bierze pod uwagę nie tylko informacje, które użytkownik mu dostarczył ale również jego własne odpowiedzi. Może tak jak mi, zdarzyło Ci się pisać z ChatGPT i po jakimś czasie wpadał w błędne koło własnych odpowiedzi.
Do czego najlepiej nadaje się model LLM?
Skoro już wiemy, że odpowiedź generowana przez LLM składa się z tokenów, to teraz możemy przejść do tego jak przebiega ten proces.
Model tworzy odpowiedź krok po kroku, generując jeden token naraz. Oznacza to, że cały proces wymaga wielokrotnego powtórzenia, aż do momentu zakończenia odpowiedzi. Możemy to zaobserwować na przykład podczas korzystania z ChatGPT czy Gemini, gdzie odpowiedź pojawia się stopniowo.
Dodatkowo, model bazuje na całej dotychczasowej konwersacji. Generując kolejny token, uwzględnia nie tylko informacje przesłane przez użytkownika, ale także swoje wcześniejsze odpowiedzi. Przez co potrafi utrzymać spójność i kontekst rozmowy. Jednak ta cecha może czasami prowadzić do problemów. Przykładowo, jeśli model „wpadnie” w błędne schematy wnioskowania, może wielokrotnie powtarzać podobne lub nieprecyzyjne odpowiedzi, tworząc tzw. błędne koło.
Jak korzystasz na przykład z ChatGPT, to pewnie zauważyłeś, że czasem generuje on podobne odpowiedzi, odchodząc od głównego tematu. To typowy przykład błędnego koła modelu.
Fine-tuning a RAG
Fine-tuning i RAG (Retrieval Augmented Generation) to techniki, które pozwalają na dostosowanie i ulepszenie modelu, ukierunkowując jego zachowanie lub rozszerzając jego wiedzę w danym obszarze.
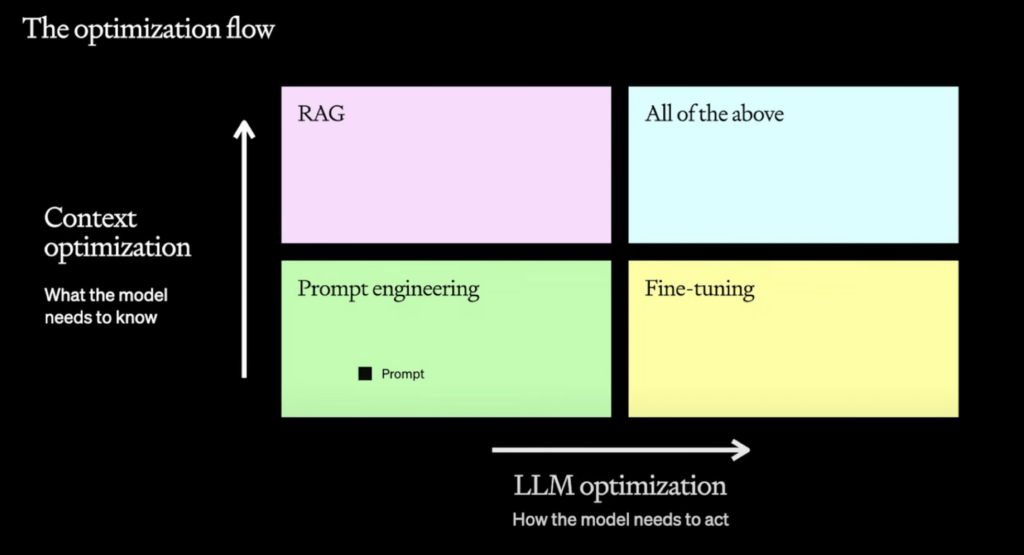
źródło: OpenAI
Fine-tuning
Zacznijmy od fine-tuning’u. Jest to douczenie modelu jak ma się zachowywać, a ściślej mówiąc w jaki sposób ma generować odpowiedzi. W praktyce oznacza to, że dostarczamy mu zestaw danych zawierający przykłady, które mają nauczyć go pożądanych akcji.
Przykład: załóżmy, że chcemy aby model na podstawie wiadomości od supportu, automatycznie stworzył odpowiednie zadanie i przypisał do dedykowanego zespołu. Fine-tuning pozwoli na wytrenowanie modelu na zestawie takich przykładów, dzięki czemu nauczy się on jak formułować odpowiedzi, tak aby później zintegrować je z naszym systemem do zarzadzania zadaniami na przykład Jira czy Trello.
Korzyści Fine-tuning’u
- Wyższa jakość odpowiedzi: Model staje się bardziej precyzyjny i lepiej dopasowany do specyficznych potrzeb.
- Optymalizacja zasobów: Dobrze wytrenowany model wymaga mniej tokenów do wygenerowania poprawnej odpowiedzi, co przekłada się na szybsze działanie i niższe koszty.
- Dostosowanie do unikalnych danych: Możemy zaadaptować model do pracy z danymi specyficznymi dla naszej organizacji, np. używając wewnętrznego słownictwa czy procesów.
Choć sam proces fine-tuningu, może być drogi, na dłuższą metę generuje oszczędności dzięki efektywniejszemu wykorzystaniu zasobów. Będzie to szczególnie ważne w środowiskach, gdzie liczba zapytań jest duża, a każda optymalizacja przynosi znaczące korzyści.
RAG (Retrieval Augmented Generation)
W podejściu RAG model jest wzbogacany o dodatkowy kontekst, co pozwala na zwiększenie jego efektywności i dokładności. Standardowe modele LLM po zakończeniu treningu nie mają dostępu do internetu ani do aktualnych danych, co może stanowić wyzwanie, jeśli potrzebujemy informacji, które nie były częścią danych treningowych modelu.
RAG rozwiązuje ten problem, umożliwiając modelowi odwoływanie się do zewnętrznych źródeł wiedzy, takich jak dokumentacje, bazy danych czy inne zasoby.
Jak działa RAG w praktyce?
Załóżmy, że uczymy się nowej technologii i chcemy, aby model LLM pomagał nam zrozumieć jej zawiłości. Wystarczy załadować do systemu pełną dokumentację tej technologii, a następnie zintegrować ją z modelem. Dzięki temu model będzie mógł odpowiadać na nasze pytania, odwołując się do nowych, precyzyjnych informacji, które wcześniej nie były dla niego dostępne.
Przykłady zastosowań:
- Wsparcie techniczne: Możemy dostarczyć modelowi dokumentację naszego produktu, co sprawi, że model stanie się pomocnym asystentem wspierającym użytkowników, a jeśli nie poradzi sobie z problemem, może poprosić człowieka o pomoc.
- Usprawnienie wewnętrznych procesów: Wgrywając dokumenty firmowe, procedury czy bazy danych, stworzymy narzędzie, które pomoże pracownikom szybko odnaleźć potrzebne informacje lub rozwiązać problemy.
- Edukacja: LLM może być używany jako interaktywny nauczyciel, który odpowiada na pytania w oparciu o dedykowane materiały edukacyjne.
Korzyści RAG:
- Aktualność: Możemy wzbogacać model o najnowsze informacje, bez konieczności czasochłonnego retreningu.
- Elastyczność: RAG pozwala na dostosowanie modelu do specyficznych potrzeb w różnych dziedzinach.
- Oszczędność czasu i kosztów: Dzięki dynamicznemu dostarczaniu kontekstu unikamy kosztów fine-tuningu na dużych zestawach danych.
Technika RAG jest w stanie przekształcić modele LLM w dynamicznych asystentów, którzy mogą działać jako eksperci w każdej dziedzinie, pod warunkiem dostarczenia im odpowiednich danych. Na przykład jako support na pierwszej linii kontaktu z klientem.
Podsumowanie
Generatywna sztuczna inteligencja, a w szczególności modele LLM, stały się już elementem elementem pracy wielu programistów. Choć zazwyczaj kojarzymy je z interfejsami czatu na przykład ChatGPT czy Gemini. Takie modele możemy wykorzystać, równie skutecznie, do bardziej specjalistycznych zadań, takich jak analiza tekstu czy jego korekta.
Poprzez dostarczenie modelowi szerszego kontekstu, większej liczby danych lub specjalizowaniu go pod konkretne zadanie, jesteśmy w stanie znacząco podnieść jakość generowanych odpowiedzi. Co więcej, tak zoptymalizowane modele mogą prowadzić do zmniejszenia kosztów operacyjnych. Szczególnie, gdy zastosujemy mniejsze modele, które, dzięki odpowiedniemu fine-tuningowi, będą w stanie niemal bezbłędnie wykonywać zadania porównywalne do tych realizowanych przez większe modele, ale przy mniejszych nakładach zasobów.