Czym jest baza wektorowa?
Baza wektorowa w matematyce odnosi się do zbioru wektorów, które są liniowo niezależne i rozpinają całą przestrzeń wektorową. Mówiąc prościej, bazy wektorowe to sposób na opisanie przestrzeni w najprostszy możliwy sposób przy pomocy minimalnej liczby elementów.
Baza wektorowa w kontekście AI
Podczas tworzenia rozwiązań opartych o modele LLM, zwłaszcza w kontekście gromadzenia i wyszukiwania danych mamy do czynienia z bazami wektorowymi oraz vector embeddings. Polega to na sprawdzaniu semantycznej bliskości data pointów, gdzie dane wejściowe (np. pytania użytkowników, dokumenty, treści) są przekształcane na reprezentacje wektorowe. Pozwalają one na efektywne porównywanie i wyszukiwanie danych, nawet jeśli nie mają one identycznego słownictwa, ale są semantycznie podobne.
Embedding
Embedding to tworzenie wektorów z danych. Proces ten umożliwia przeniesienie semantycznego znaczenia do liczb. Tego typu mechanizmy spotykasz regularnie używając silników rekomendacji, asystentów głosowych, czy tłumacza języków.
Jako wektor może być zapisany paragraf, tekst, pojedyncze słowo itd. Do tego celu niezbędny jest Embedding Model, który odpowiada za zmianę danych na wektory.
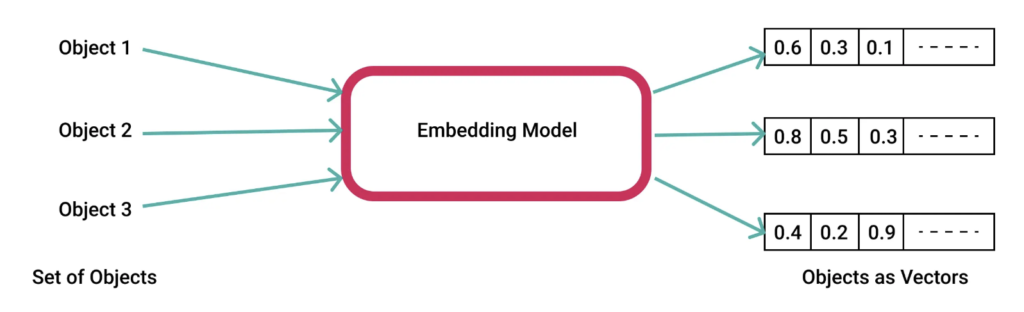
źródło: pinecone.io
Zastosowanie baz wektorowych
Wyobraźmy sobie zbiór danych zapisanych w bazie wektorowej. Zwizualizujmy je sobie na przestrzeni trójwymiarowej (w rzeczywistości wektory moga być od blisko 100 do 4000 wymiarowe).
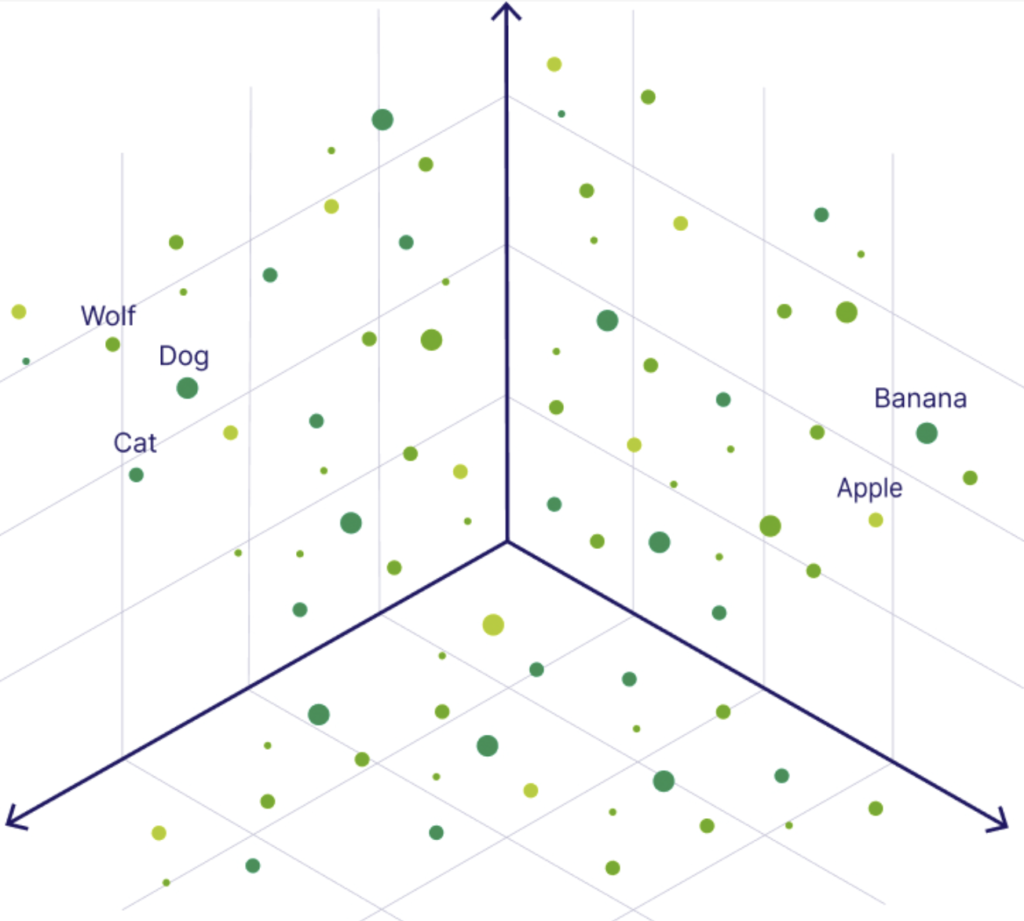
źródło: weaviate.io
Widzimy, że pies, kot i wilk są położone blisko siebie. Wilki oraz psy są położone blisko siebie, dlatego że psy są bliskimi potomkami wilków. Podobnie koty i psy, są dość klasycznymi zwierzętami.
Natomiast po drugiej stronie mamy jabłko i banan. Są to owoce, dlatego leżą blisko siebie oraz po przeciwnej stronie od, bo nie są w żaden sposób skojarzone ze zwierzętami.
Widać na tym przykładzie jak działa baza wektorowa. W tym momencie jeśli użytkownik zacząłby wyszukiwać słowo banan, jest duże prawdopodobieństwo, że także dostałby informacje o jabłku.
Podsumowanie
Vector Embedding to liczbowa reprezentacja danych różnych typów, takich jak dane tekstowe, obrazy czy dźwięki. Potrafi one uchwycić semantyczne relacje między obiektami danych, co umożliwia odnajdywanie podobnych data points, identyfikując ich najbliższe sąsiedztwo w wysokowymiarowej przestrzeni wektorowej.