Wprowadzenie do tematu
W dzisiejszym świecie przetwarzania języka naturalnego (NLP) coraz częściej spotykamy rozwiązania, które łączą różne podejścia, aby uzyskać jak najlepsze rezultaty. W tym wpisie przyjrzymy się dwóm podejściom: RAG (Retrieval Augmented Generation) oraz lżejszemu wyszukiwaniu wektorowemu. Celem artykułu jest omówienie, kiedy warto zastosować bardziej zaawansowany mechanizm RAG, a kiedy prostsze, wektorowe wyszukiwanie wystarczy.
Definicja i działanie RAG
Czym jest RAG?
RAG, czyli Retrieval Augmented Generation, to hybrydowe podejście, które łączy generowanie treści przez modele językowe z wyszukiwaniem informacji z zewnętrznych źródeł. W praktyce oznacza to, że model nie tylko polega na swojej wewnętrznej wiedzy, ale także aktywnie wyszukuje dodatkowe informacje, aby udzielić bardziej precyzyjnych i kontekstualnych odpowiedzi.
Jak działa RAG?
Mechanizm RAG opiera się na dwóch głównych komponentach:
- Moduł wyszukiwania: Wyszukuje odpowiednie fragmenty tekstu lub dokumenty, które mogą zawierać potrzebne informacje.
- Moduł generacji: Na podstawie zebranych danych generuje odpowiedź, łącząc wiedzę z wyszukiwania z własnymi możliwościami modelu językowego.
Przykłady zastosowań RAG
- Systemy Q&A: Użytkownik zadaje skomplikowane pytanie, a system wyszukuje informacje w dokumentach i generuje spójną odpowiedź.
- Chatboty: Wykorzystanie RAG pozwala chatbotom na udzielanie bardziej precyzyjnych i kontekstowych odpowiedzi.
- Wyszukiwarki kontekstowe: Łącząc wyszukiwanie informacji z generowaniem odpowiedzi, można uzyskać narzędzie, które nie tylko znajduje dokumenty, ale też interpretuje ich treść.
Czym jest wyszukiwanie wektorowe?
Podstawy wyszukiwania wektorowego
Wyszukiwanie wektorowe polega na reprezentacji dokumentów i zapytań jako wektorów w przestrzeni wielowymiarowej. Dzięki temu możliwe jest porównywanie podobieństwa między różnymi tekstami za pomocą miar takich jak cosinusowa miara podobieństwa. Podejście to jest stosunkowo proste i szybkie, co czyni je idealnym rozwiązaniem do szybkiego wyszukiwania podobnych dokumentów lub fragmentów tekstu.
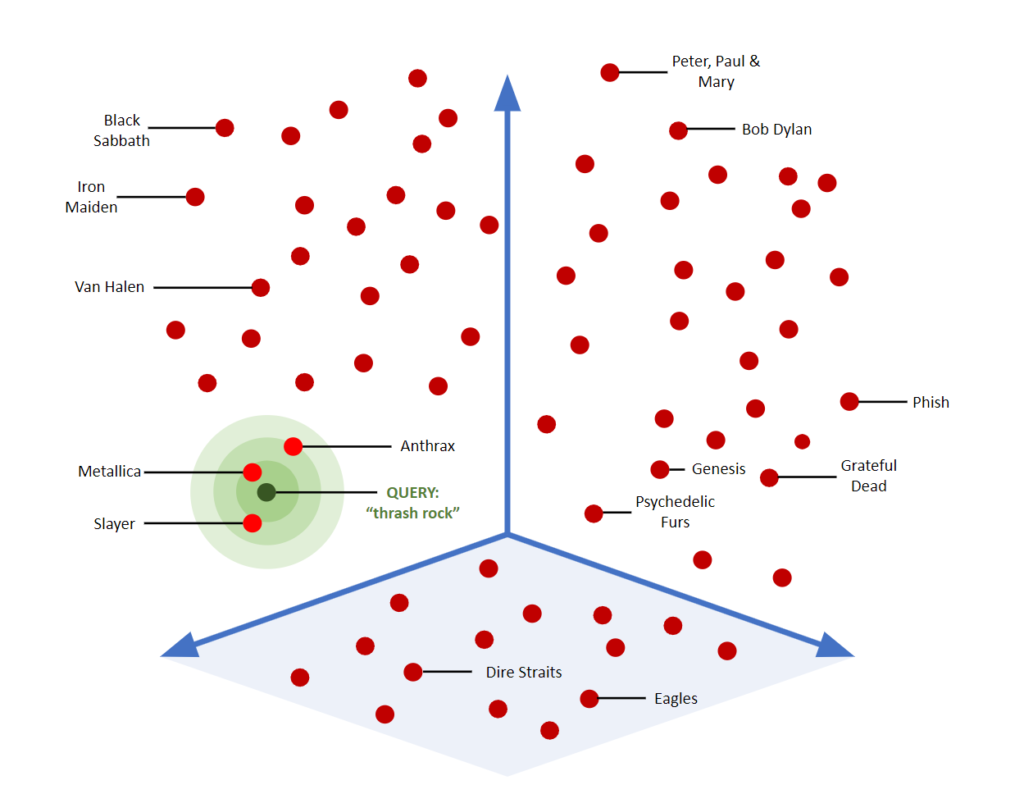
źródło: https://www.couchbase.com/blog/what-is-vector-search/
Zastosowania prostszego podejścia
- Szybkie wyszukiwanie: Idealne w sytuacjach, gdy kluczowa jest szybkość i nie jest potrzebne generowanie nowych treści.
- Podstawowe analizy: Sprawdzi się tam, gdzie wystarczy znaleźć dokumenty najbardziej zbliżone do zapytania.
- Systemy o ograniczonych zasobach: Mniejsze wymagania obliczeniowe sprawiają, że to rozwiązanie jest atrakcyjne w zastosowaniach, gdzie zasoby sprzętowe są ograniczone.
Kiedy warto używać RAG?
Skomplikowane zapytania i kontekst
RAG jest szczególnie przydatne, gdy zapytania są złożone i wymagają:
- Dodatkowego kontekstu: Gdy odpowiedź nie opiera się jedynie na prostym wyszukiwaniu, ale wymaga złożonej analizy danych.
- Łączenia informacji z różnych źródeł: W sytuacjach, gdy potrzebujemy zebrać dane z wielu dokumentów i je skonsolidować.
- Wysokiej precyzji: Gdy błąd lub niekompletna informacja może wpłynąć na jakość odpowiedzi, np. w systemach medycznych czy finansowych.
Kiedy wyszukiwanie wektorowe jest wystarczające?
Scenariusze prostszych aplikacji
- Szybkość działania: Gdy najważniejszym kryterium jest czas reakcji, a zapytania są stosunkowo proste.
- Niskie wymagania obliczeniowe: Idealne rozwiązanie dla aplikacji lub systemów pracujących na ograniczonych zasobach.
- Mniej skomplikowane zadania: Gdy nie jest konieczne generowanie nowych treści, a wystarczy jedynie wskazanie najbardziej zbliżonych dokumentów czy fragmentów tekstu.
Porównanie obu podejść
Zalety RAG
- Wysoka precyzja
- Elastyczność
Wady RAG
- Wymagania obliczeniowe
- Złożoność implementacji
Zalety wyszukiwania wektorowego
- Szybkość
- Mniejsze koszty
- Łatwość implementacji
Wady wyszukiwania wektorowego
- Brak generowania treści
- Ograniczenia kontekstualne
Podsumowanie
- Wybierz RAG, gdy Twoje zapytania są skomplikowane, wymagają dodatkowego kontekstu i precyzyjnych odpowiedzi, a zasoby sprzętowe nie stanowią ograniczenia.
- Postaw na lżejsze wyszukiwanie wektorowe, gdy kluczowa jest szybkość działania, prostota implementacji oraz mniejsze zapotrzebowanie na obliczenia, a zapytania są stosunkowo proste